
APIs, ABIs, & Shared Libraries
What the heck is an ABI anyways?

Us engineer types are familiar with the concept of an API — the interface through which you communicate with a piece of software. Often the software you use is designed by someone else, and the outward-facing interface they provide makes up its public API, which conceals implementation details that evolve more freely.
API design is so critical that there are massive guides dedicated to getting it right:
🎓 Quick primer: API compatibility
In the biz you'll hear people talk about API changes that are "backwards-compatible," or ones that introduce "breaking changes." These describe how much work the consumer of software has to put in to continue using it as it evolves.
Here's a simple Node.js script that reads the contents of a file:
const fs = require('fs');
const data = fs.readFileSync('./data.json', 'utf8');
console.log(data);The API documentation for readFileSync() says the first argument is the path of the file, and the second argument can be a string representing the encoding. If the next version of Node.js switched the order of these parameters, this would be a "breaking change," and my program would give the wrong result or an error; in a compiled language like C++ it might not even build. To adopt this hypothetical "breaking" version of Node, I'd need to update my usage of its APIs.
The issue of "API compatibility" is ubiquitous, present everywhere from interpreted languages like Node.js & Python, to Web APIs, and client-side projects like Chromium. For maintainers of software, judging API compatibility feels pretty natural because it's all determined at the "programming" level, where we spend all our time.
🤯 ABI compatibility
Lurking underneath the comparatively simple world of API compatibility is the esoteric and tangled one of ABI compatibility. The B stands for binary, and binary compatibility has a unique set of constraints. But what's it even mean to be binary-compatible, and what is an ABI anyways?!
Taking a step back, we see it's common for smaller software projects to bake their dependencies directly into their binary. In C++, this means #include'ing all your dependency header files and then compiling the implementation files together at the same time.
$ g++ main.cc third-party/library1.cc third-party/library2.ccSince everything's tucked into one binary, when using a third-party library we only need to consider its programming interface to get our code to work correctly. But for highly-modular client-side software, it's common to compile dependencies separately and link the resulting binaries together later.
🎓 Quick primer: Linking
When your software and its dependencies are compiled separately, nothing changes from a programming perspective — your source files still directly reference their dependency libraries & call their APIs — but in order to run your software you have to tell "the linker" where your dependency binaries actually live.
There are three ways to link to external libraries:
Static linking: For static libraries, typically with the
.aextension ("archive"). Simple but inefficient: when compiling, the entire archive gets copied into the referencing code in the linking phase✅ Dynamic linking: For shared libraries (
.dllon Windows,.soon Unix,.dylibon macOS)Dynamic loading: For loading shared libraries at runtime manually by your own code, via a function like
dlopen()(see this example in Chromium).
If you want to learn more about these I'd urge you to read Scientific Programming's paper on this topic.
In this essay we care about dynamic linking which is perhaps the most common way to depend on third-party binaries. It's special because it lets multiple programs depend on the same library binary without duplicating its contents each time (unlike static linking), so it's very memory-efficient. Shared libraries are loaded at runtime automatically by a dynamic loader (`ld.so` on Unix), which involves an on-the-fly linking phase to patch-up dependencies across binaries before execution starts. You can even view a binary's shared library dependencies:
$ ldd my_binary
my_binary:
libmydependency.so
/usr/lib/libc++.1.dylib
# Use `otool -L` on macOS or
# depends.exe on Windows.This trivial C++ binary depends on one custom shared library, and also libc++, a compiled implementation of the entire C++ standard library (std::vector, std::set, etc.) packaged with the Clang compiler.
When updates are made to a shared library on your computer, every piece of software that links against that library gets those updates for free the next time they run — of course this requires that the two library binaries remain compatible across versions. Ensuring that your library's binary is backwards-compatible with older binaries that depend on it as it evolves is precisely what ABI compatibility is.
But what’s an ABI?
And how does it differ from a plain old API? I first asked these questions when reading documentation for Mojo, the interprocess communication library in Chromium, and its sidekick ipcz:
Note that the Mojo Core shared library presents a stable C ABI designed with both forward- and backward-compatibility [...]
- mojo README.md
The library is meant to be consumed exclusively through the C ABI defined in [...]
- ipcz README.mdWhy were these beautifully written, advanced C++ libraries all exposing their public APIs in C, which obviously can't express the complex types inside? I set out to answer this question and report my findings here.
At first glance, most conventional explanations of an ABI were inscrutable and left much to be desired, like this one from Linux System Programming, or the ones on Wikipedia & Stack Overflow. They made sense at a distance but when you don't think in terms of CPU Architecture 101 every day, they don't buy you much. Describing an ABI as consisting of "function calling conventions" and the "size and layout of basic types" felt abstract. "How your code is stored inside the library file" makes me nod, but doesn't show me how it differs from an API. If I change the order of arguments in my API, of course that will lead to some binary change when I recompile. So far APIs & ABIs seemed 1:1, which wasn't very useful.
The key is realizing that while your code communicates with a library through its API, your binary communicates with a library through its binary interface, which is indeed largely derived from its API in code, but also by many other things.
The easiest way to observe what shapes a binary interface apart from the code in your program is with name mangling. For example, C is a very simple language that doesn't support function overloads:
void func() {}
void func(int i) {} // Not allowed in C!Because every function has a unique name, when creating a shared library, all stringified function names that end up in the binary for the linker to reference later are identical to their names in code, and stable across compilers. You can view a binary's symbol table with nm on Unix, which shows everything your library exposes:
// main.c
void PublicAPI() {}
void PublicAPI2(int i) {}
void PublicAPI3(double d, int i) {}
$ clang main.c a.out
$ nm -gmU a.out
0000000100003f74 (__TEXT) external _PublicAPI
0000000100003f78 (__TEXT) external _PublicAPI2
0000000100003f88 (__TEXT) external _PublicAPI3Having to name your functions uniquely to account for different parameters is tedious, so luckily since C++ supports function overloads. But this just pushes the problem down to the compiler, which needs to produce unique names for each overload based on its parameters. This is called name mangling, and the conventions for carrying it out are compiler-dependent, making it an easy-to-visualize source of binary incompatibility. Consider the difference in mangled function names that GCC & Microsoft Visual C++ come up with for the same code:
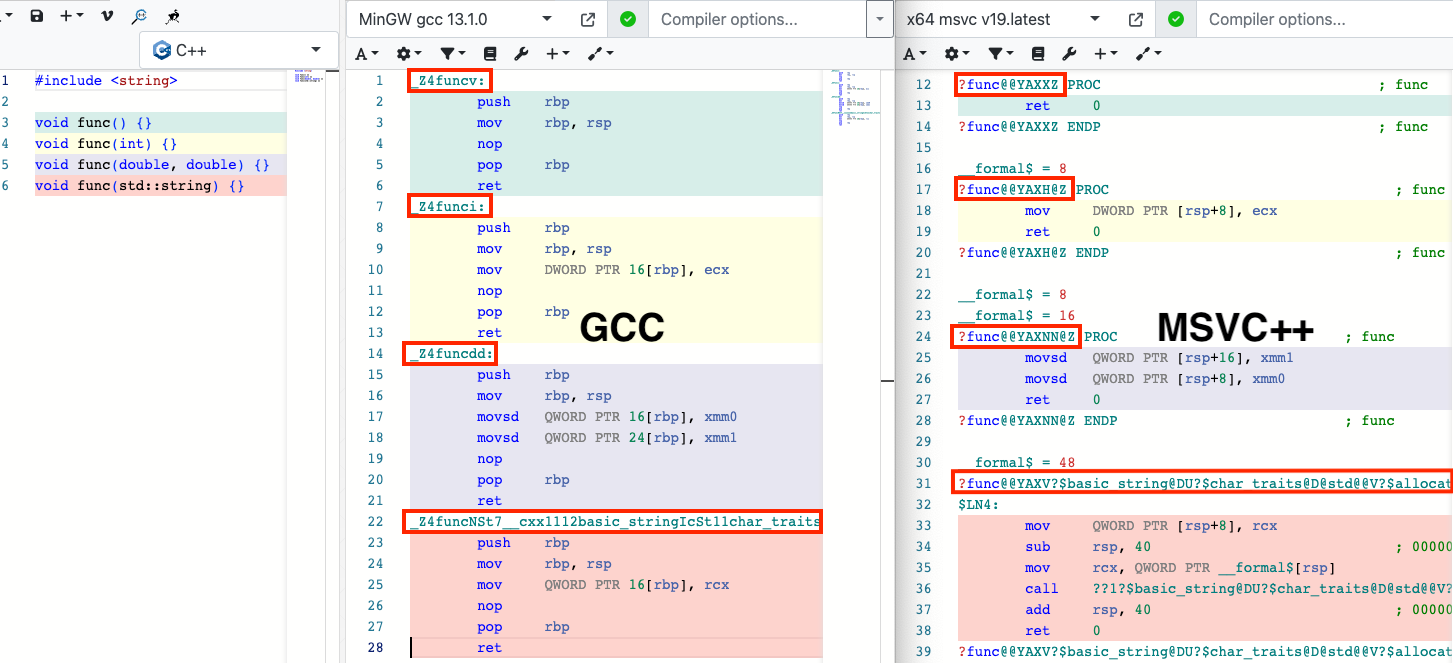
If on Windows your code was compiled with GCC but depended on a library compiled with MSVC, your code's usage of the library APIs will be ✅ spot on ✅, but at runtime your binary will try to reference those APIs by the mangled names GCC came up with, when they live in the library's binary under the MSVC-chosen names. This is valid because the C++ standard doesn't define an ABI, so compilers are free to mangle names however they want since they don't impact the language semantics (only the interface of the resulting binary). In practice, divergent name mangling is the least notable cause of binary incompatibility1 — we'll cover others later — but this toy example helps us visualize the problem: different compilers cannot be trusted to produce C++ binaries that play nicely together2.
This explains why many heroic C++ libraries expose their public APIs in pure C. Because C is such a dirt simple language, compilers don't really pursue novel ways of spitting out binaries for the same program; they all just follow the standard binary conventions of the CPU architecture they're running on. In fact, the ABI specification for a given architecture describes the bare minimum primitives used to construct binaries, like: call a subroutine, return a value, pass in arguments, & jump to a memory address. In other words, it describes how CPU instructions are used to implement basic programming semantics. That's pretty much all a simple language like C needs, so there isn't any room or appetite for compilers to innovate further when turning C code into binary code. This makes the ABI specification of your architecture the de facto C language ABI, meaning any C program's ABI will be identical across compilers on the same platform. You can view the x86-x64 ABI specification here, which says:
No attempt has been made to specify an ABI for languages other than C. However, it is assumed that many programming languages will wish to link with code written in C, so that the ABI specifications documented here apply there too.
C++, on the other hand, has wildly complex features that go far beyond basic binary primitives, including virtual function tables, r-value references, and move semantics. These are way more abstract than basic CPU instructions, leaving lots of wiggle room for compilers to implement these language features with different combinations of CPU instructions to achieve the same semantics. The results are vastly different binary representations of the same C++ program, depending on your compiler.
By taking advantage of C's stable ABI, you can write complicated libraries in any language, and compile them with any compiler. As long as they expose themselves with an API using basic C linkage conventions, then the place where they intersect will speak the same language regardless of compiler, and that's all that matters.
Breaking your ABI
Now that we grasp the importance of maintaining ABI compatibility across software versions, let's pretend you're the maintainer of a popular shared library that millions of computers have in binary form. How do you make sure each new version of your library is binary-compatible with older compiled programs that depend on it? Is it as easy as not introducing breaking changes to your API (like renaming a function or reordering its arguments)?
Actually, no. If you're not careful, you can easily introduce an ABI change without touching your API. When this happens, if you're lucky, existing binaries will fail to run when loading your library, and in the worst case they'll behave fine most of the time, but infrequently crash or give slightly-wrong results. Maintaining ABI compatibility is crucial for backwards-compatibility, and here we'll give examples of how easily things can go wrong, to further our understanding of what goes into an ABI. All examples come from my ABI GitHub repository, so you can experiment with them locally.
ABI-breaking changes can be hard to detect; since they don't require code changes to adopt, you can't rely on compiler errors to guide you along. For example, imagine the MyBrowser project uses your library v1.0, and a month later you publish v1.1 with some fixes. You recompile MyBrowser from scratch with library v1.1 to confirm you didn't break anything, and get no compiler errors. This can give you a false sense of security that nothing "external" has changed in your library, so older versions of MyBrowser will continue to work just fine with your new library — but that's not always true. Consider a library that exposes this Point class:
class Point {
public:
void SetX(int x) {x_ = x;}
void SetY(int y) {y_ = y;}
private:
int x_;
int y_;
};Suppose an updated version adds an `int z_;` member, so that Points can be 3D. It seems harmless: older programs compiled against the library will just ignore the new member (operating two-dimensionally), while newer programs can take advantage of it to do more interesting things. After all, this is how we'd evolve the API to introduce new features without breaking old code, right?
Unfortunately this example violates the One Definition Rule, which states that there must be only one definition of an object at any time. With this change, older programs believe sizeof(Point) is equivalent to two integers, while the library and new programs sees it as three integers large. Consider an older compiled program:
std::vector<library::Point> points = library::GetPoints();
for (const library::Point& point : points) {
point->Print();
}The new library binary hands over a vector of 12-byte classes to the embedder, who was expecting a vector of 8-byte classes. When different components of a program are working on different definitions of the same object, you get undefined behavior, and the loop above will surely break in an unexpected way!
We're finally getting a feel for how touchy an ABI is compared to an API. As we've seen, adding a (private) member to a class in your API is one way to break compatibility, but here are some others that you can probably guess will do it too:
Removing members
Rearranging the order of members
Adding virtual functions
It's even possible to suffer ABI breaks without touching your code at all! The C++ STL is implemented in the shared libraries libstdc++ for GCC & libc++ for Clang, and insofar as you use any of its types in your API, your ABI depends on the ABI of these binaries that ship with your compiler. For example, if GCC compiler engineers fixed a bug in std::string that required adding a member to that class, all code compiled with an older version of libstdc++ would have to be recompiled with the new one as to not violate the ODR. In fact, C++11 introduced this very ABI-breaking change and ruffled a lot of feathers (see this discussion)!
While the C++ standards committees don't explicitly specify an ABI, they can only make changes that compiler vendors agree to implement, and they won't make changes that significantly break their ABI, as it would send shockwaves of pain through the developer ecosystem. This has led to several C++ language proposals being rejected on the grounds of ABI compatibility, like this trivial change to std::pair, major improvements to native regex, and dozens more. Jason Turner talks about this in his presentation Break ABI to Save C++. With that said, C++ is a complicated language whose STL ABIs are bound to break in the fullness of time, have done so in the past, and already vary across compilers despite valiant attempts at compatibility. To learn more about this, I'd recommend the following talks:
Just like there are massive guides dedicated to getting API design right, there are guides to help you maintain ABI stability in your software. They, and the distributors of popular libraries you use without knowing it, tell you the sure-fire way of achieving ABI stability is to expose your library with pure C (or C++ with C linkage via extern "C"):
Use only plain C on the actual ABI stable boundaries of the library; do not use C++ or STL containers (or carefully choose a stable enough subset of it);
This keeps your API/ABI simple, concealing all moving parts inside as implementation details. But to do this, you need to go as far as avoiding exporting complex types in your API, including most structs with members. This leaves you with a big table of functions that deal largely in opaque pointer-ey types, like this:
extern "C" {
typedef int32_t Result;
// Cross-platform shared memory allocator.
Result AllocateSharedMemory(
size_t num_bytes, // in
uint32_t flags, // in
uintptr_t output_buffer); // out
}Opaque pointer-ey types? APIs with "output" parameters that return "status" codes? What does this remind you of? Probably the C APIs you use to communicate with your OS kernel like open() & read(), right? They don't use sexy types & pretty APIs, but they do perform critical actions and then give you weird handles to their results, like ints that represent files. You then feed these handles back into other APIs to perform actions on the underlying objects that you never reference directly. We see these similarities because in reality, the kernel is the ultimate shared library, when you think about it, and C ABIs are written in a similar fashion.
So if you write a library like this, how then do you avoid the inconvenience of dealing with these ugly APIs that are kinda painful to use? Well, often for every low-level ABI you consume, there's a thin, high-level wrapper library you can statically bake into your program to make more convenient use of the low-level stuff. Since it's only a helper layer over the low-level stuff, it doesn't need to be shared by all binaries that also use the low-level one; each program can use a different wrapper, or none at all.
Let's end with a practical example of this: the Vulkan graphics library. Vulkan is a low-level, cross-platform library for 3D graphics powered by GPUs, and is often consumed as a shared library. You can always use it directly — like you might use `pthread_mutex_lock()` in C — but several bindings layers have been written to provide more convenient use of it from other languages, like ash for Rust, and Vulkan-Hpp for C++. These aren't distributed as shared libraries alongside the Vulkan binary, but are instead baked right into the programs using them (often as static libraries) just as you would Google's Abseil library when using absl::Mutex as an elegant wrapper over the kernel's implementation of a mutex, and its corresponding C APIs.
Enormous thanks to Ken Rockot and Daniel Cheng for helping me understand many of the complicated concept that took me way too long to grasp.
As mentioned, while name mangling is perhaps the most obvious way to observe binary incompatibility, it's actually the least interesting, and maybe one of the least frequent causes of binary incompatibility. In practice, even if compilers promised to mangle names according to a standard for the sake of the tooling industry, other significant compiler-specific differences result in more serious binary incompatibilities. Since the C++ feature set is so rich, compilers can choose to implement the same language semantics differently under the hood, making different tradeoffs and optimizations that emerge at the binary level.
In practice, compilers actually attempt to be as ABI-compatible with each other as they can, so observing egregious ABI incompatibility is harder than you think. There are two notable examples:
Clang's C++ ongoing attempt at ABI-compatibility with MSVC when compiling on Windows — but note that ABI compatibility is indeed ongoing, will never be perfect, and isn't standardized by any external resource.
The Itanium C++ ABI Specification that GCC and Clang try and adhere to on Unix — in fact one of Clang's design goals was to be ABI-compatible with GCC from the beginning.
Notwithstanding these attempts at ABI compatibility, there does not exist an official standard that every C++ compiler must adhere to on a given platform, and insofar as different compilers are ABI-compatible, it is in spite of the absence of an official standard, not because of it — the whole effort at ABI compatibility is driven by compiler-vendor-driven.
Moreover, the same compiler won't always have a stable ABI across different versions of itself. MSVC only adopted a stable ABI as of 2015, and for example, the ABI of std::span breaks in between GCC10 and GCC11, as does std::string in between GCC4 and GCC5. This is in addition to the various bugs that will always crop up over time.